Semilandmark analysis#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
from ktch.datasets import load_landmark_trilobite_cephala
from ktch.landmark import GeneralizedProcrustesAnalysis, combine_landmarks_and_curves
from ktch.plot import configuration_plot, explained_variance_ratio_plot, morphospace_plot
Load trilobite cephalon dataset#
This dataset contains 2D landmark and semilandmark configurations of trilobite cephala (head shields). Each specimen has 16 fixed landmarks and 4 curves with semilandmarks (12, 20, 20, and 20 points respectively).
data = load_landmark_trilobite_cephala()
landmarks = data.landmarks
curves = data.curves
print("landmarks shape:", landmarks.shape)
print("number of curves per specimen:", len(curves[0]))
for i, c in enumerate(curves[0]):
print(f" curve {i}: {c.shape[0]} points")
landmarks shape: (300, 16, 2)
number of curves per specimen: 4
curve 0: 12 points
curve 1: 20 points
curve 2: 20 points
curve 3: 20 points
df_meta = pd.DataFrame(data.meta)
df_meta.head()
| genus | species | ref_pic | locality | formation | min_age | max_age | format | has_scale | |
|---|---|---|---|---|---|---|---|---|---|
| 1020_Liu_1977 | Hunanolenus | Hunanolenus genalatus | Liu 1977 | Hunan | Huaqiao | Paibian | Paibian | xml | True |
| 1023_Liu_1977 | Huangshiaspis | Huangshiaspis transversus | Liu 1977 | Fenghuang area | Tingziguan | Jiangshanian | Jiangshanian | xml | True |
| AMF27749 | Weania | Weania semicircularis | Vanderlaan y Ebach 2015 | Glen William Road | Flagstaff | Middle Visean | Upper Visean | xml | True |
| AMNH_28896 | Eldredgeops | Eldredgeops raNAmilleri | Burton and Eldredge 1974 | NaN | NaN | Eifelian | NaN | tps | True |
| AMNH_28902 | Viaphacops | Viaphacops stummi | Eldredge 1973 | NaN | NaN | Eifelian | NaN | tps | True |
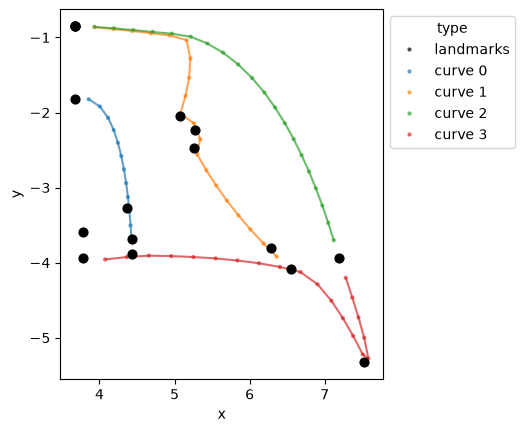
Visualize raw data#
Plot a single specimen, distinguishing fixed landmarks from curve semilandmarks.
specimen_idx = 0
def _specimen_to_df(landmarks, curves, specimen_idx):
"""Convert a single specimen's landmarks and curves to a DataFrame."""
rows = []
for i in range(landmarks.shape[1]):
rows.append((*landmarks[specimen_idx, i], "landmarks"))
for ci, curve in enumerate(curves[specimen_idx]):
for pt in curve:
rows.append((*pt, f"curve {ci}"))
df = pd.DataFrame(rows, columns=["x", "y", "type"])
df.index.name = "coord_id"
return df
def _curve_links(n_landmarks, curves_for_specimen):
"""Generate links connecting consecutive curve points."""
links = []
offset = n_landmarks
for curve in curves_for_specimen:
for j in range(len(curve) - 1):
links.append([offset + j, offset + j + 1])
offset += len(curve)
return links
df_specimen = _specimen_to_df(landmarks, curves, specimen_idx)
links_curves = _curve_links(landmarks.shape[1], curves[specimen_idx])
curve_types = [f"curve {i}" for i in range(len(curves[specimen_idx]))]
curve_colors = sns.color_palette(n_colors=len(curve_types))
palette_specimen = {"landmarks": "black"}
palette_specimen.update(dict(zip(curve_types, curve_colors)))
ax = configuration_plot(
df_specimen, links=links_curves, hue="type",
palette=palette_specimen, s=10, alpha=0.7,
)
lm = df_specimen[df_specimen["type"] == "landmarks"]
ax.scatter(lm["x"], lm["y"], c="black", s=40, zorder=3)
<matplotlib.collections.PathCollection at 0x7f3d97707750>
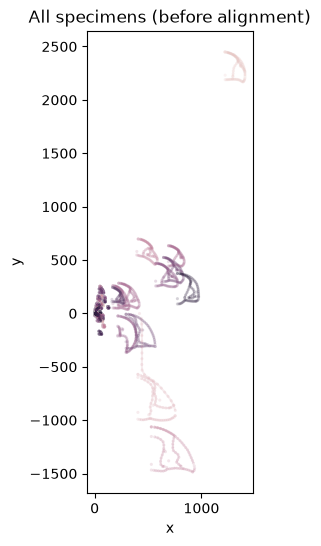
Plot all specimens overlaid before alignment.
rows = []
for i in range(landmarks.shape[0]):
for j in range(landmarks.shape[1]):
rows.append((i, *landmarks[i, j]))
for curve in curves[i]:
for pt in curve:
rows.append((i, *pt))
df_all = pd.DataFrame(rows, columns=["specimen_id", "x", "y"])
df_all = df_all.set_index("specimen_id")
df_all["coord_id"] = df_all.groupby(level=0).cumcount()
df_all = df_all.set_index("coord_id", append=True)
fig, ax = plt.subplots(figsize=(6, 6))
configuration_plot(
df_all, links=links_curves, hue="specimen_id",
color="gray", color_links="gray", alpha=0.2, s=5, ax=ax,
)
ax.get_legend().remove()
ax.set_title("All specimens (before alignment)")
Text(0.5, 1.0, 'All specimens (before alignment)')
Combine landmarks and curves#
combine_landmarks_and_curves() merges the fixed landmarks and curve semilandmarks
into a single configuration array and generates the slider matrix that defines the sliding topology.
The curve_landmarks parameter specifies which landmarks anchor each curve.
Each curve’s semilandmarks slide along the tangent direction, with the
specified landmarks serving as fixed endpoints.
combined, slider_matrix, curve_info = combine_landmarks_and_curves(
landmarks,
curves,
curve_landmarks=data.curve_landmarks,
)
print("combined shape:", combined.shape)
print("slider_matrix shape:", slider_matrix.shape)
print("curve_info:", curve_info)
combined shape: (300, 88, 2)
slider_matrix shape: (72, 3)
curve_info: {'n_landmarks': 16, 'n_curve_points': 72, 'curve_offsets': [16, 28, 48, 68], 'curve_lengths': [12, 20, 20, 20]}
The slider matrix has shape (n_sliders, 3) where each row is [before_index, slider_index, after_index].
All semilandmarks are included in the slider matrix. For curve endpoints,
the before/after neighbor is the anchoring landmark.
print("First 5 rows of slider_matrix:")
print(slider_matrix[:5])
First 5 rows of slider_matrix:
[[ 1 16 17]
[16 17 18]
[17 18 19]
[18 19 20]
[19 20 21]]
Reshape the combined array to 2D (n_specimens, n_points * n_dim) for GPA input.
Specimens containing NaN values are excluded.
X = combined.reshape(combined.shape[0], -1)
nan_mask = np.any(np.isnan(X), axis=1)
print(f"Specimens with NaN: {nan_mask.sum()} / {X.shape[0]}")
X_clean = X[~nan_mask]
df_meta_clean = df_meta[~nan_mask].reset_index(drop=True)
print(f"Specimens used for analysis: {X_clean.shape[0]}")
Specimens with NaN: 15 / 300
Specimens used for analysis: 285
GPA with semilandmark sliding#
Pass the curves parameter to GeneralizedProcrustesAnalysis to enable semilandmark sliding
during Procrustes superimposition. Semilandmarks slide along their curve tangent directions
to minimize bending energy.
The tol parameter controls convergence tolerance for the iterative GPA algorithm.
gpa = GeneralizedProcrustesAnalysis(n_dim=2, curves=slider_matrix, tol=1e-3)
shapes = gpa.fit_transform(X_clean)
print("shapes shape:", shapes.shape)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 70 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 69 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
/home/runner/work/ktch/ktch/ktch/landmark/_procrustes_analysis.py:432: UserWarning: Rank-deficient sliding system: rank 71 < 72. Tangent directions may be degenerate (zero-length or collinear).
x_slid = slide_func(x_rot, mu, curves)
shapes shape: (285, 176)
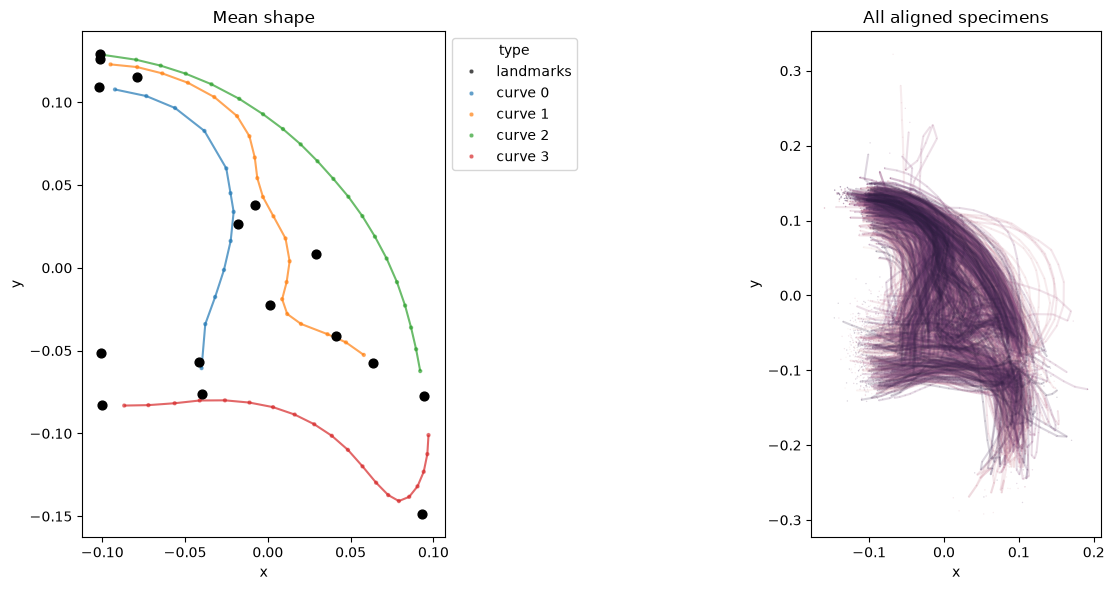
Visualize the aligned shapes.
n_points = combined.shape[1]
n_dim = 2
def _shapes_to_df(shapes, n_points, n_dim, n_landmarks, curve_info):
"""Convert GPA output array to a MultiIndex DataFrame with type labels."""
rows = []
for i in range(shapes.shape[0]):
specimen = shapes[i].reshape(n_points, n_dim)
for j in range(n_points):
rows.append((i, j, *specimen[j]))
df = pd.DataFrame(rows, columns=["specimen_id", "coord_id", "x", "y"])
# Add type column
types = ["landmarks"] * n_landmarks
for ci, length in enumerate(curve_info["curve_lengths"]):
types.extend([f"curve {ci}"] * length)
df["type"] = df["coord_id"].map(lambda j: types[j])
return df.set_index(["specimen_id", "coord_id"])
df_aligned = _shapes_to_df(
shapes, n_points, n_dim, curve_info["n_landmarks"], curve_info,
)
# Mean shape
mean_shape = shapes.mean(axis=0).reshape(n_points, n_dim)
df_mean = pd.DataFrame(mean_shape, columns=["x", "y"])
df_mean["type"] = df_aligned.loc[0, "type"].values
df_mean.index.name = "coord_id"
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Mean shape with color by type, then overlay landmarks in black
palette_mean = {"landmarks": "black"}
palette_mean.update(dict(zip(curve_types, curve_colors)))
configuration_plot(
df_mean, links=links_curves, hue="type",
palette=palette_mean, s=10, alpha=0.7, ax=axes[0],
)
lm_mean = df_mean.iloc[:curve_info["n_landmarks"]]
axes[0].scatter(lm_mean["x"], lm_mean["y"], c="black", s=40, zorder=3)
axes[0].set_title("Mean shape")
# All aligned specimens
configuration_plot(
df_aligned, links=links_curves, hue="specimen_id",
color="gray", color_links="gray", alpha=0.2, s=1, ax=axes[1],
)
axes[1].get_legend().remove()
axes[1].set_title("All aligned specimens")
plt.tight_layout()
PCA#
pca = PCA(n_components=10)
pc_scores = pca.fit_transform(shapes)
df_pca = pd.DataFrame(
pc_scores,
columns=[f"PC{i+1}" for i in range(pc_scores.shape[1])],
)
df_pca = df_pca.join(df_meta_clean[["genus"]])
df_pca.head()
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | PC8 | PC9 | PC10 | genus | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.125228 | -0.162647 | 0.004561 | 0.050726 | 0.019523 | 0.050510 | -0.016427 | 0.043711 | 0.002174 | -0.025951 | Hunanolenus |
| 1 | -0.041252 | -0.236899 | 0.140655 | 0.112496 | 0.036621 | 0.002261 | 0.001618 | 0.024187 | -0.056088 | 0.014121 | Huangshiaspis |
| 2 | 0.009868 | -0.111546 | -0.027055 | -0.132076 | 0.009976 | -0.019524 | 0.101439 | -0.009635 | 0.039078 | -0.067129 | Weania |
| 3 | 0.142255 | 0.099790 | 0.069591 | -0.034382 | -0.008973 | 0.026952 | 0.003910 | 0.059150 | -0.012461 | 0.021385 | Eldredgeops |
| 4 | 0.088966 | 0.111502 | 0.055935 | -0.030005 | 0.049822 | 0.041755 | 0.008725 | 0.068558 | -0.035017 | 0.035339 | Viaphacops |
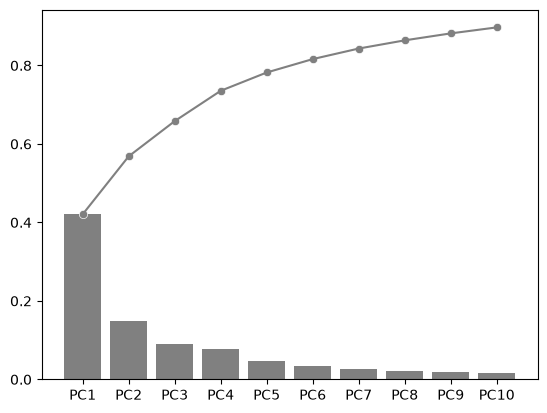
fig, ax = plt.subplots()
explained_variance_ratio_plot(pca, ax=ax, verbose=True)
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10
Explained Variance Ratio (EVR) 0.4207 0.1478 0.0897 0.0773 0.0466 0.0342 0.0269 0.0209 0.0177 0.0153
Cumsum of EVR 0.4207 0.5685 0.6582 0.7355 0.7821 0.8163 0.8432 0.8641 0.8818 0.8971
<Axes: >
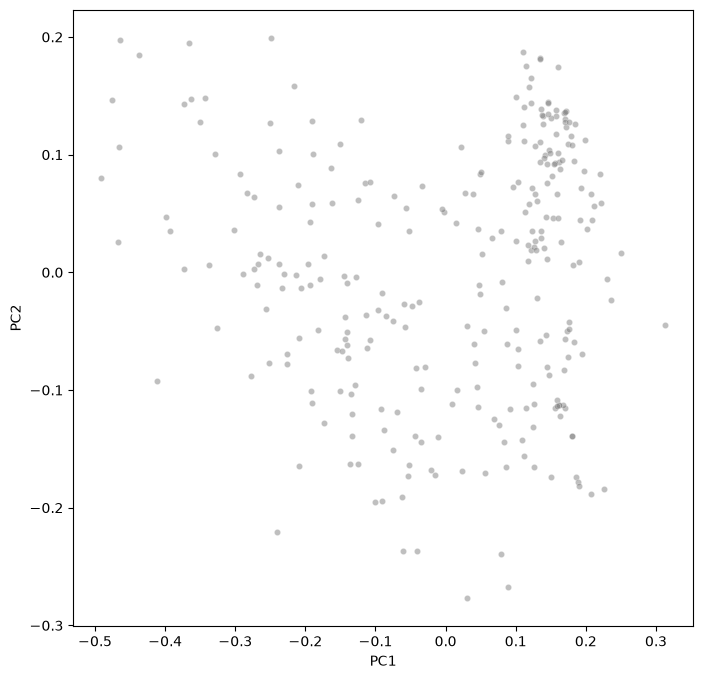
Morphospace visualization#
fig, ax = plt.subplots(figsize=(8, 8))
sns.scatterplot(
data=df_pca,
x="PC1",
y="PC2",
ax=ax,
c="gray",
alpha=0.5,
s=20,
)
ax.set(xlabel="PC1", ylabel="PC2")
[Text(0.5, 0, 'PC1'), Text(0, 0.5, 'PC2')]
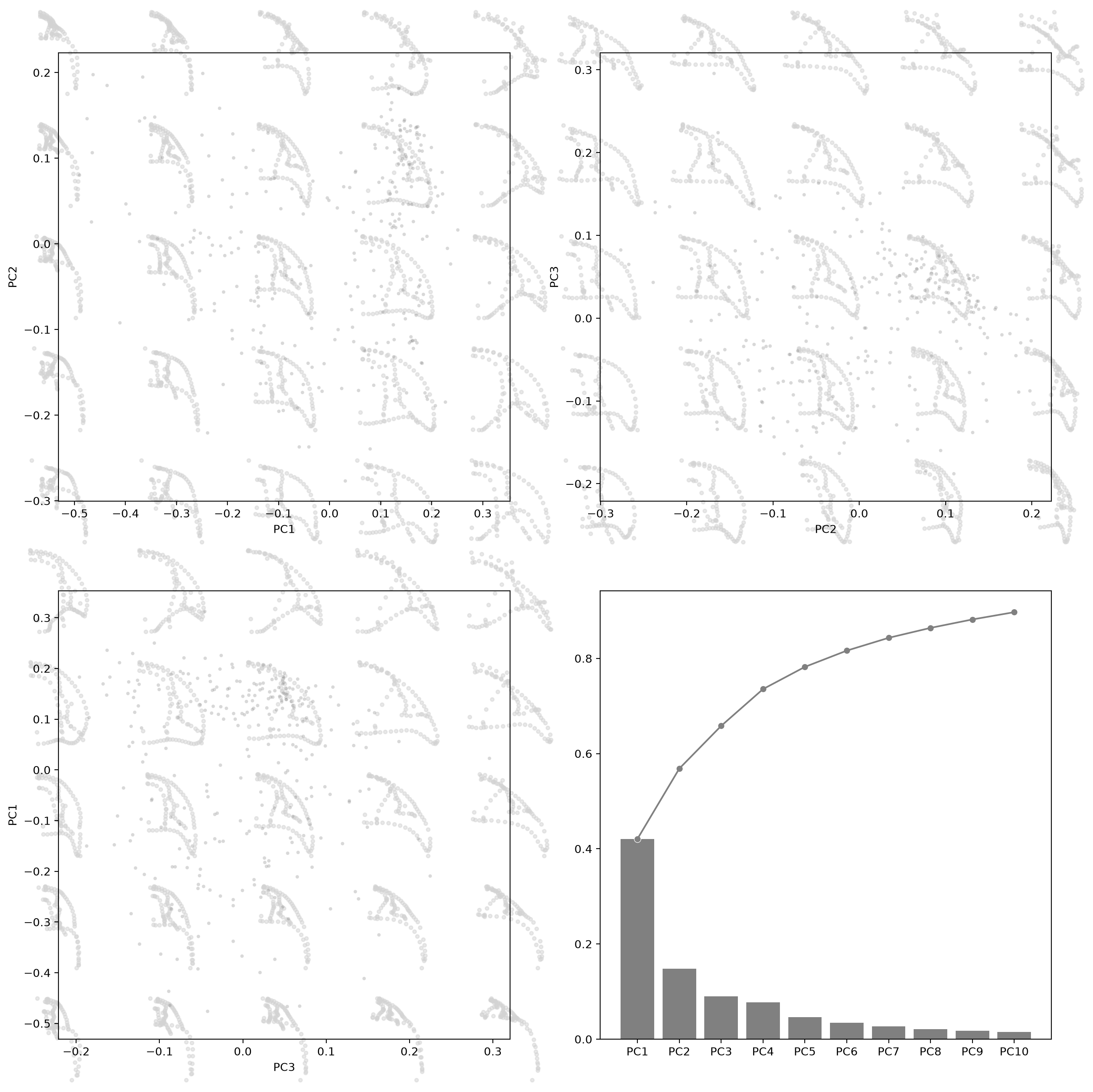
fig, axes = plt.subplots(2, 2, figsize=(16, 16), dpi=200)
for ax, (i, j) in zip(axes.flat[:3], [(0, 1), (1, 2), (2, 0)]):
morphospace_plot(
data=df_pca,
x=f"PC{i + 1}", y=f"PC{j + 1}",
reducer=pca,
n_dim=2,
shape_type="landmarks_2d",
components=(i, j),
n_shapes=5,
shape_alpha=0.5,
ax=ax,
scatter_kw=dict(c="gray", alpha=0.3, s=10),
)
explained_variance_ratio_plot(pca, ax=axes[1, 1], verbose=True)
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10
Explained Variance Ratio (EVR) 0.4207 0.1478 0.0897 0.0773 0.0466 0.0342 0.0269 0.0209 0.0177 0.0153
Cumsum of EVR 0.4207 0.5685 0.6582 0.7355 0.7821 0.8163 0.8432 0.8641 0.8818 0.8971
<Axes: >